

Las representaciones de malla de escenas 3D son esenciales para muchas aplicaciones, desde el desarrollo de activos AR/VR hasta gráficos por computadora. Sin embargo, crear estos activos 3D sigue siendo tedioso y requiere mucha habilidad. Esfuerzos recientes han utilizado modelos generativos, como modelos de difusión, para producir de manera efectiva imágenes de alta calidad a partir de texto en un mundo bidimensional. Estas tecnologías democratizan con éxito la producción de contenido al reducir las barreras para producir imágenes que incorporen contenido seleccionado por el usuario. Un nuevo campo de investigación ha intentado utilizar técnicas comparables para crear modelos 3D a partir de texto. Sin embargo, los métodos existentes tienen inconvenientes y necesitan más generalidad para los modelos 2D de texto a imagen.
Lidiar con la escasez de datos de entrenamiento en 3D es una de las principales dificultades en la creación de modelos en 3D porque los conjuntos de datos en 3D son mucho más pequeños que los que se utilizan en muchas otras aplicaciones, como el ajuste de fotografías en 2D. Por ejemplo, los métodos que utilizan la moderación 3D en vivo a menudo se limitan a conjuntos de datos de modelos básicos, como ShapeNet. Las técnicas recientes superan estas limitaciones de datos al formalizar la construcción 3D como un problema de optimización iterativo en el dominio de la imagen, mejorando el potencial expresivo de los modelos de texto a imagen 2D a 3D. La capacidad de producir formas arbitrarias (neuronales) a partir de texto se demuestra por su capacidad para generar objetos 3D almacenados en una representación de campo de radiación. Desafortunadamente, escalar estas técnicas para producir texturas y texturas 3D del tamaño de una habitación puede ser un desafío.
Es difícil garantizar que la salida sea densa y coherente en las vistas externas y que las representaciones incluyan todas las características necesarias, como paredes, pisos y muebles, al crear escenas masivas. La red sigue siendo la representación preferida para muchas actividades de usuarios finales, incluida la oferta de tecnología asequible. Investigadores de TU Munich y la Universidad de Michigan proponen una técnica que extrae cuadrículas 3D a escala de escena de modelos 2D de texto a imagen disponibles comercialmente para resolver estas deficiencias. Su técnica utiliza la pintura de interiores y la percepción de profundidad monocromática para crear un paisaje iterativo. Utilizando la técnica de estimación de profundidad, crean la primera cuadrícula creando una imagen a partir de texto y proyectándola de nuevo en tres dimensiones. Luego, el modelo se ve repetidamente desde nuevos ángulos.

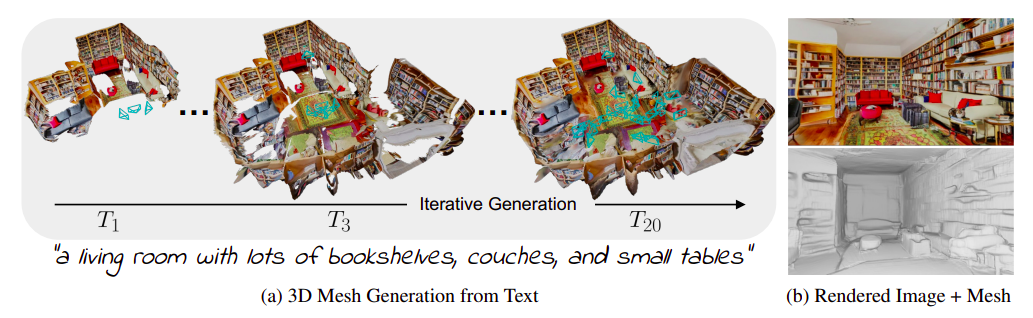
Para cada uno, pintan sobre cualquier espacio en las imágenes mostradas antes de fusionar el contenido generado en la cuadrícula (Fig. 1a). Dos factores clave en el diseño de su enfoque de generación iterativa son cómo seleccionan las escenas y cómo integran el material de escena generado con la arquitectura existente. Inicialmente, seleccionan puntos de vista de rutas predefinidas que cubren una gran parte del material de la escena y, luego, seleccionan puntos de vista de forma adaptativa para llenar los espacios vacíos. Para producir transiciones suaves cuando el contenido generado se fusiona con la cuadrícula, alinean los dos mapas de profundidad y eliminan las áreas del modelo con texturas distorsionadas.
Juntas, estas opciones proporcionan modelos 3D a gran escala y a escala de escena (Fig. 1b) que pueden representar una variedad de habitaciones y contener texturas atractivas y geometrías uniformes. Entonces, sus aportes son los siguientes:
• Una técnica que usa modelos 2D para convertir texto en una imagen y una sola estimación de profundidad para elevar cuadros a una imagen 3D al crear una escena repetitiva.
• Un método que crea mallas 3D de escenas interiores a escala de habitación con hermosas texturas y geometrías a partir de cualquier entrada de texto. Pueden producir texturas y geometrías uniformes y sin distorsiones utilizando los métodos propuestos de alineación de profundidad y fusión de mallas.
• Selección de perspectiva personalizada en dos etapas que primero toma muestras de las posiciones de la cámara desde los ángulos ideales para la colocación de los muebles y el diseño del área y luego llena los espacios para proporcionar una malla hermética.
escanear el papelY proyectoY github. Todo el crédito por esta investigación es para los investigadores de este proyecto. Además, no olvides unirte Sub Reddit de 16k+MLY canal de discordiaY Boletín electrónicodonde compartimos las últimas noticias de investigación de IA, interesantes proyectos de IA y más.


Anish Teeku es consultor en prácticas en MarktechPost. Actualmente está cursando sus estudios universitarios en Ciencia de Datos e Inteligencia Artificial en el Instituto Indio de Tecnología (IIT), Bhilai. Pasa la mayor parte de su tiempo trabajando en proyectos destinados a aprovechar el poder del aprendizaje automático. Su interés de investigación es el procesamiento de imágenes y le apasiona crear soluciones a su alrededor. Le gusta comunicarse con la gente y colaborar en proyectos interesantes.